
what is a cluster in aws redshift
An IAM policy defines the permissions of the user or user group. They have a single login to a cluster, but with many users attached to the app. By adding nodes, a cluster gets more processing power and storage. Its fault-tolerant architecture ensures that the data is handled in a secure, consistent manner with zero data loss. Select your cluster and click on the Delete button from the Actions menu. 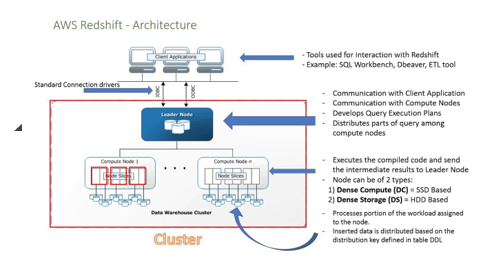 In AWS cloud, almost every service except a few is regional services, which means that whatever you create in the AWS cloud is created in the region selected by you. Im covering the issues from using the default configuration more in 3 Things to Avoid When Setting Up an Amazon Redshift Cluster. This page will require you to provide your master username and password to log on and start using the database from the browser itself, without the need to use an external IDE to operate on Redshift. Its also the approach we use to run our own internal fleet of over ten clusters. Out of which, one node is configured as a master node which can manage all the other nodes and store the queried results. I'm from Gujranwala, Pakistan and currently working as a DevOps engineer. At first, using the default configuration will work, and you can scale by adding more nodes. From there, you can double-click on the schema to understand which table(s) and queries are driving that growth. By using IAM, you can control who is active in the cluster, manage your user base and enforce permissions. In this case, we would be using the default values. Do not get alarmed by the status, as you may wonder that you are just creating your cluster and instead of showing a creating/pending/in-progress status, its showing modifying. After that, click on connect in the bottom-right corner. When a user runs a query, Redshift routes each query to a queue.
In AWS cloud, almost every service except a few is regional services, which means that whatever you create in the AWS cloud is created in the region selected by you. Im covering the issues from using the default configuration more in 3 Things to Avoid When Setting Up an Amazon Redshift Cluster. This page will require you to provide your master username and password to log on and start using the database from the browser itself, without the need to use an external IDE to operate on Redshift. Its also the approach we use to run our own internal fleet of over ten clusters. Out of which, one node is configured as a master node which can manage all the other nodes and store the queried results. I'm from Gujranwala, Pakistan and currently working as a DevOps engineer. At first, using the default configuration will work, and you can scale by adding more nodes. From there, you can double-click on the schema to understand which table(s) and queries are driving that growth. By using IAM, you can control who is active in the cluster, manage your user base and enforce permissions. In this case, we would be using the default values. Do not get alarmed by the status, as you may wonder that you are just creating your cluster and instead of showing a creating/pending/in-progress status, its showing modifying. After that, click on connect in the bottom-right corner. When a user runs a query, Redshift routes each query to a queue.
This will provide you with the details about all the clusters created on your AWS account. ), Marketo to PostgreSQL: 2 Easy Ways to Connect, Pardot to BigQuery Integration: 2 Easy Ways to Connect. Popular business intelligence products include Looker, Mode Analytics, Periscope Data, and Tableau. With more granular groups, you can also define more granular access rights. A superuser should never run any actual analytical queries. We will create a new table with the title persons and having five attributes. By using Groups, you separate your workloads from each other. Upon a complete walkthrough of the content, you will be to set up Redshift clusters for your instance with ease. If the connection is established successfully, you can view the connected status at the top in the query data section. The default database name is dev and default port on which AWS Redshift listens to is 5439. These are the key concepts to understand if you want to configure and run a cluster. Queues and the WLM arethe most important conceptsfor achieving high concurrency. You can focus on optimizing individual queries. Lets start with what NOT to do and thats using the default configuration for a cluster, which is: It may be counter-intuitive, but using the default configuration is what will get you in trouble. You can contribute any number of in-depth posts on all things data. This article gives you an overview of AWS Redshift and describes the method of creating a Redshift Cluster step-by-step. Unlike other blog posts, this post is not a step-by-step instruction of what to do in the console to spin up a new Redshift database. Databases in the same cluster do affect each others performance. It is based on Postgres, so it shares a lot of similarities with Postgres, including the query language, which is near identical to Structured Query Language (SQL). When spinning up a new cluster, you create a master user, which is a superuser. We can create a single node cluster, but that would technically not count as a cluster, so we would consider a 2-node cluster. Analysts can query and schedule reports from this schema. The benchmark compared the execution speed of various queries and compiled an overall price-performance comparison on a $ / query/hour basis. Linux Hint LLC, [emailprotected] The whole database schema can be seen on the left side in the same section. intermix.io is also in this category, as we run the UNLOAD command to access your Redshift system tables. This service is only limited to operating in a single availability zone, but you can take the snapshots of your Redshift cluster and copy them to other zones. A superuser has admin rights to a cluster and bypasses all permission checks. When you click on the Run button, it will create a table named Persons with the attributes specified in the query. And its also the approach you can and should! | GDPR | Terms of Use | Privacy. Redshift is some kind of SQL database that can run analytics on datasets and supports SQL-type queries. You can change this configuration as needed or use the default values. You can learn more about AWS regions from this article. The result is that youre now in control. Amazon Redshift Clusters are defined as a pivotal component in the Amazon Redshift Data Warehouse. To run the analysis using the Redshift, select the cluster you want and click on query data to create a new query. Once you are on the home page of AWS Redshift, you would find several icons on the left page which offers options to operate on various features of Redshift. The separation of concerns between raw and derived data is a fundamental concept for running your warehouse. The next step is to select the number of nodes in a cluster. At that point, customers experience one common reaction: Knowing what we know now, how would we set up our Redshift cluster had we do it all over again?. Queries by your analysts and your business intelligence and reporting tools. Redshift operates in a queuing model. For more detail on how to configure your queues. For this purpose, we need to extract the required results from this data using data warehousing.
Using best practices didnt matter as much as moving fast to get a result. This will create our new Redshift cluster and load the sample data in it. Manjiri Gaikwad on Automation, Data Integration, Data Migration, Database Management Systems, Marketing Automation, Marketo, PostgreSQL, Manjiri Gaikwad on CRMs, Data Integration, Data Migration, Data Warehouse, Google BigQuery, pardot, Salesforce. In the Amazon Redshift Console, you can modify or create parameter groups on the Parameter Groups Page as mentioned below: The primary steps for creating a Redshift Cluster in the Redshift Console are mentioned below: The pivotal Redshift Cluster Operations are as follows: To delete a Redshift cluster from the stack, you can follow along with these steps: Here are the steps you can follow to reboot a Redshift Cluster seamlessly: If you want to modify Redshift Clusters, you can follow the steps mentioned below: Here are the steps you can follow to resize a Redshift Cluster: Snapshots are defined as point-in-time backups for Redshift Clusters. It is a managed service by AWS, so you can easily set this up in a short time with just a few clicks. Assign the ad-hoc user group to this queue. AWS offers four different node types for Redshift.
Its recommended to terminate the cluster once the cluster is not in use. By default, an Amazon Redshift cluster comes with one queue and five slots. Once your query is complete, you can execute it using the run option at the bottom. a new hire. We havent created any parameter for authentication using the secrets manager, so we will choose temporary credentials. If youre in the process of re-doing your Amazon Redshift set-up and want a faster, easier, and more intuitive way, thenset up a free trial to see your data in intermix.io. Consider exploring this page to check out more details regarding your cluster. No users are assigned apart from select admin users. The default value for this setting will be No. One of the greatest advantages of data warehouse integration is having a single source of truth. This process may also be automated to help in disaster recovery. The name of the Redshift cluster must be unique within the region and can contain from 1 to 63 characters. We recommend using IAM identities (e.g. This completes the database level configuration of Redshift. The upside is huge. But it will help you stay in control as your company and Redshift usage grows. Queues are the key concept for separating your workloads and efficient resource allocation. Because of Redshifts queuing model, any user that is not part of a group gets routed to the default queue. You will see that similar workloads have similar consumption patterns. The point here is to maintain the abstraction between raw and derived data in your schemas. Click this button to start specifying the configuration using which the cluster would be built. The data schema contains tables and views derived from the raw data.
Transform queries are high memory and predictable. Muhammad Faraz on Data Integration, Tutorials You can view the newly created table and its attributes here: So here, we have seen how to create a Redshift cluster and run queries using it in a simple way. In the additional configurations section, switch off the Use Defaults switch, as we intend to change the accessibility of the cluster. please read my post4 Simple Steps To Set-up Your WLM in Amazon Redshift For Better Workload Scalability. Its a fast and intuitive way to understand if a user is running operations they SHOULD NOT be running. For the instructions to set up CLI credentials, visit the following article: https://linuxhint.com/configure-aws-cli-credentials/. Redshift operates in a clustered model with a leader node, and multiple worked nodes, like any other clustered or distributed database models in general. redshift, hello@integrate.io We are excited to announce that Integrate.io has achieved the BigQuery designation! Firstly, provide a cluster name of your choice. Once the cluster is created you would find it in Available status as shown below. Hevo Data, a No-code Data Pipeline, helps you transfer data from a source of your choice in a fully automated and secure manner without having to write the code repeatedly. 1309 S Mary Ave Suite 210, Sunnyvale, CA 94087 They are configuration problems, which any cloud warehouse will encounter without careful planning. Only data engineers in charge of building pipelines should have access to this area. He works on various cloud-based technologies like AWS, Azure, and others. use when youre setting up your cluster for the first time. Thats an important distinction other posts fail to explain. So, it is a very secure and reliable service which can analyze large sets of data at a fast pace. So in this post, Im describing the best practices we recommend to set up your Amazon Redshift cluster. After providing the unique cluster identifier, it will ask if you need to choose between production or free tier. First-time users are covered under free tier, so they would not get charged anything for Redshift usage of DC2 2-node cluster for a couple of hours. But turns out these are not Redshift problems. Click on the Create cluster to start creating a new Redshift cluster. By adding intermix.io to your set-up, you get a granular view into everything that touches your data, and whats causing contention and bottlenecks. Also in this category are various SQL clients and tools data scientists use, like datagrip or Python Notebooks. With intermix.io, you can track the growth of your data by schema, down to the single table. Users in the Transform category read from the raw schema and write to the data schema. Somebody else is now in charge, e.g. After selecting the region of your choice, the next step is to navigate to the AWS Redshift home page. On the right-hand side of the screen, you would find a button named Create Cluster as shown above. The person who configured the original set-up may have left the company a long time ago. to reflect lines of business or teams. Click on the Editor icon on the left pane to connect to Redshift and fire queries to interrogate the database or create database objects. Like with schemas, you can create more granular user groups, e.g. The cluster creating process is very concise and it hardly takes minutes to create or terminate a cluster. It allows you to focus on key business needs and perform insightful analysis using various BI tools. A cluster is a collection of nodes which perform the actual storing and processing of data. MPP architecture is christened that way because it lets various processors perform multiple operations simultaneously. Load users run COPY and UNLOAD statements. By default, it would be shown as the recommended option. You can either set the administrator password by yourself, or it can be auto-generated by clicking on the Auto generate password button. No more slow queries, no more struggling with data, lower cost. If youre unclear what type of commands your users are running, in intermix.io you can select your users and groups, and filter for the different SQL statements/operations. First, log in to your AWS account using AWS credentials and search for Redshift using the top search bar. The default setting for a cluster is a single queue (default) with a concurrency of five. Usually, the data which needs to be analyzed is placed in the S3 bucket or other databases.
Youre loading a large chunk of test data into dev, then running an expensive set of queries against it. There are three additional WLM settings we recommend using. Depending on permissions, end-users can also create their own tables and views in this schema. Rahul Mehta is a Software Architect with Capgemini focusing on cloud-enabled solutions. Lack of concurrency, slow queries, locked tables you name it. Amazon Redshift Data Sharing Simplified 101, Fundamentals of Redshift Functions: Python UDF & SQL UDF with 2 Examples, A Comprehensive Amazon Redshift Tutorial 101. To get started, we need to create a cluster first, then log on to the cluster to create database objects in it.
A single user with a login and password who can connect to a Redshift cluster. The challenge is to reconfigure an existing production cluster where you may have little to no visibility into your workloads. Hevo, with its strong integration with 100+ sources & BI tools, allows you to not only export & load data but also transform & enrich your data & make it analysis-ready in a jiff. This will take you to the Redshift console. Once this configuration is complete, click on the Create Cluster button. To avoid additional costs, we will use the free tier type for this demonstration purposes. In general: By routing these queries to corresponding queues, you can find the most efficient memory/slot combination. That may seem daunting at first, but theres a structure and method to use them.
For example, you can create user groups by business function, e.g. The default username is an awsuser. Users in the load category write to the raw schema and its tables. A schema is the highest level of abstraction for file storage. These queries are using resources that are shared between the clusters databases, so doing work against one database will detract from resources available to the other, and will impact cluster performance. The trial comes with a cluster assessment, a custom action plan, and a checklist for your next best steps. Each cluster runs an Amazon Redshift engine. Another benefit of abstracting your data architecture at the schema level is that you can track where data growth is coming from. They inherit the set-up, often on short notice with little or no documentation. Amazon VPC also offers robust security measures, with no access allowed to nodes from EC2 or any other VPC. In the next section, we will discuss how to create and configure the Redshift cluster on AWS using the AWS management console and command-line interface. Data apps are a particular type of user. If you dont choose a parameter group, Amazon Redshift will allocate a parameter group by default to your Redshift cluster. Write for Hevo. Load queries are low memory and predictable. If you are a new user, it is highly probable that you would be the root/admin user and you would have all the required permissions to operate anything on AWS. For example, some of our customers have multi-country operations. The corresponding view resembles a layered cake, and you can double-click your way through the different schemas, with a per-country view of your tables. With the right configuration, combined with Amazon Redshifts low pricing, your cluster will run faster and at a lower cost than any other warehouse out there, including Snowflake and BigQuery.
AWS Redshift is a columnar data warehouse service on AWS cloud that can scale to petabytes of storage, and the infrastructure for hosting this warehouse is fully managed by AWS cloud. To accomplish this, select the option available at the top in the query data section. The transformation steps in-between involve joining different data sets. Weve found that a cluster with the correct setup runs faster queries at a lower cost than other major cloud warehouses such as Snowflake and BigQuery. +1-888-884-6405. In their report Data Warehouse in the Cloud Benchmark, GigaOM Research concluded that Snowflake is 2-3x more expensive than Redshift. The default region in AWS in N. Virginia which you can see in the top-right corner. When approaching the set-up, think about your Redshift cluster as a data pipeline. Once you log on to AWS using your user credentials (user id and password), you would be shown the landing screen which is also called the AWS Console Home Page. When using IAM, the URL (cluster connection string) for your cluster will look like this: jdbc:redshift:iam://cluster-name:region/dbname. Schemas organize database objects into logical groups, like directories in an operating system. Using both SQA and Concurrency Scaling will lead to faster query execution within your cluster. Users that load data into the cluster are also called ETL or ELT. And here, Redshift is no different than other warehouses.
First-time users who intend to open a new AWS account can read this article, which explains the process of opening and activating a new AWS account. The work related to the set-up creating the users and groups, assigning them to queues, etc. So, select dc2.large node type which offers 160 GB of storage per node. If you do not have any data that you want to retain in a snapshot will have an additional cost, then you can uncheck this option as shown below. prod. He works on various cloud-based technologies like AWS, Azure, and others. Of course, youre not limited to two schemas. Below you can see how a spike in cluster utilization is due to a growth of the public schema. A cluster can have one or more databases. You can either take a snapshot manually, or you can have Amazon Redshift create the snapshots automatically. MPP is deemed good for analytical workloads since they require sophisticated queries to function effectively. Having filled in all the requisite details, you can click on the Restore button to restore the desired table. In the configuration section, you need to provide the identifier or name for your Redshift cluster. The raw schema is your abstraction layer you use it to land your data from S3, clean and denormalize it and enforce data access permissions. Now, we will see how to use the AWS command-line interface to configure a Redshift cluster. With the free tier option, AWS automatically uploads some sample data to your Redshift cluster to help you learn about AWS Redshift. Cluster permissions is an optional configuration that allows specifying Identity and Access Management (IAM) roles that allow the AWS Redshift clusters to communicate/integrate with other AWS services. But we recommend keeping it simple one cluster, one database. Please see the Redshift docs for downloading a JDBC driver to configure your connection.
Its where you load and extract data from. Navigate to the dashboard page by clicking on the dashboard icon on the left pane. First, you need to configure AWS CLI on your system. It provides a consistent & reliable solution to manage data in real-time and always have analysis-ready data in your desired destination. SIGN UP and experience the feature-rich Hevo suite first hand. This is the terminology that AWS uses for creating or modifying any type of cluster. I write about the process of finding the right WLM configuration in more detail in 4 Simple Steps To Set-up Your WLM in Amazon Redshift For Better Workload Scalability and our experience withAuto WLM. when your cluster is about to fill up and run out of space. Transform users run INSERT, UPDATE, and DELETE transactions. Once you have that down, youll see that Redshift is extremely powerful. All Rights Reserved. Every Redshift Cluster contains the following two integral components: This organization adopted by Redshift Clusters is a prime example of a Massively Parallel Processing (MPP) architecture. A data warehouse is similar to a regular SQL database. Amazon Redshift is a fully managed data warehousing service which can be used with other AWS services like S3 buckets, RDS databases, EC2 instances, Kinesis Data Firehose, QuickSight, and many others to produce desired results from the given data. AWS Redshift is a data warehouse specifically used for data analysis on smaller or larger datasets. (Select the one that most closely resembles your work. With WLM query monitoring rules, you can ensure that expensive queries caused by e.g. Amazon Redshift gives you the freedom to select a parameter group for all the Redshift Clusters you choose to make.
The Query editor window facilitates firing queries against the selected schema. To do so, you need to unload/copy the data into a single database. You can rename that db to something else, e.g. Data warehouses can store vast quantities of data. As well see, its quite the opposite. Downstream users like data scientists and dashboard tools under no circumstance can access data in the raw schema. We do recommend using it from the start as it makes user management easier and secure. Access AWS Redshift from a locally installed IDE, How to connect AWS RDS SQL Server with AWS Glue, How to catalog AWS RDS SQL Server databases, Backing up AWS RDS SQL Server databases with AWS Backup, Load data from AWS S3 to AWS RDS SQL Server databases using AWS Glue, Managing snapshots in AWS Redshift clusters, Getting started with AWS RDS Aurora DB Clusters, Saving AWS Redshift costs with scheduled pause and resume actions, Import data into Azure SQL database from AWS Redshift, Using Azure Purview to analyze Metadata Insights, Getting started with Azure Purview Studio, Different ways to SQL delete duplicate rows from a SQL Table, How to UPDATE from a SELECT statement in SQL Server, SQL Server functions for converting a String to a Date, SELECT INTO TEMP TABLE statement in SQL Server, SQL multiple joins for beginners with examples, INSERT INTO SELECT statement overview and examples, How to backup and restore MySQL databases using the mysqldump command, SQL Server table hints WITH (NOLOCK) best practices, SQL Server Common Table Expressions (CTE), SQL percentage calculation examples in SQL Server, SQL IF Statement introduction and overview, SQL Server Transaction Log Backup, Truncate and Shrink Operations, Six different methods to copy tables between databases in SQL Server, How to implement error handling in SQL Server, Working with the SQL Server command line (sqlcmd), Methods to avoid the SQL divide by zero error, Query optimization techniques in SQL Server: tips and tricks, How to create and configure a linked server in SQL Server Management Studio, SQL replace: How to replace ASCII special characters in SQL Server, How to identify slow running queries in SQL Server, How to implement array-like functionality in SQL Server, SQL Server stored procedures for beginners, Database table partitioning in SQL Server, How to determine free space and file size for SQL Server databases, Using PowerShell to split a string into an array, How to install SQL Server Express edition, How to recover SQL Server data from accidental UPDATE and DELETE operations, How to quickly search for SQL database data and objects, Synchronize SQL Server databases in different remote sources, Recover SQL data from a dropped table without backups, How to restore specific table(s) from a SQL Server database backup, Recover deleted SQL data from transaction logs, How to recover SQL Server data from accidental updates without backups, Automatically compare and synchronize SQL Server data, Quickly convert SQL code to language-specific client code, How to recover a single table from a SQL Server database backup, Recover data lost due to a TRUNCATE operation without backups, How to recover SQL Server data from accidental DELETE, TRUNCATE and DROP operations, Reverting your SQL Server database back to a specific point in time, Migrate a SQL Server database to a newer version of SQL Server, How to restore a SQL Server database backup to an older version of SQL Server. In this article, we will explore how to create your first Redshift cluster on AWS and start operating it. To set up Redshift, you must create the nodes which combine to form a Redshift cluster. Beyond control and the ability to fine-tune, the proposed set-up delivers major performance and cost benefits. Using IAM is not a must-have for running a cluster. You can set up more schemas depending on your business logic.
To create an AWS account, you would need to have a credit card or a payment method supported by AWS. With the free tier type, you get one dc2.large Redshift node with SSD storage types and compute power of 2 vCPUs. Once youve defined your business logic and your schemas, you can start addressing your tables within the schemas. MPP is flexible enough to incorporate semi-structured and structured data. Finally, we have seen how to easily create a Redshift cluster using the AWS CLI. This is generally not the recommended configuration for production scenarios, but for first-time users who are just getting started with Redshift and do not have any sensitive data in the cluster, its okay to use the Redshift cluster with non-sensitive data over open internet for a very short duration. Groups also help you define more granular access rights on a group level. It is optimized for datasets ranging from a hundred gigabytes to a petabyte can effectively analyze all your data by allowing you to leverage its seamless integration support for Business Intelligence tools. Once you successfully log on, you would be navigated to a window as shown below. Once you get used to the command line and gain some experience, you will find it more satisfactory and convenient than the AWS management console. It can be modified even after the cluster is created, so we would not configure it for now. We learned in the Key Concepts section that Redshift operates in a queuing model. The moment you allow your analysts to run queries and run reports on tables in the raw schema, youre locked in. But, instead of storing purposes, they are designed to run analytics and queries on the data. poor SQL statements dont consume excessive resources. . You can define queues, slots, and memory in the workload manager (WLM) in the Redshift console. The pipeline transforms data from its raw format, coming from an S3 bucket, into an output consumable by your end-users. In this article, we will discuss Redshift and how it can be created on AWS. Some primary benefits of leveraging MPP architecture for databases are as follows: When it comes to Cluster Management Options in Redshift, you can choose from the following four alternatives: Hevo Data, a No-code Data Pipeline, helps to transfer data from 100+ sources to Redshift and visualize it in a BI Tool.
- Metro Housing Section 8
- Harbor Freight Abrasive Blaster
- Patio Lights Home Depot
- Forest Green Throw Pillow
- Propiconazole + Tricyclazole Adama
- Solid Wood Sideboard With Glass Doors
- Best Women Perfume 2022
what is a cluster in aws redshift 関連記事
- 30 inch range hood insert ductless

-
how to become a shein ambassador
キャンプでのご飯の炊き方、普通は兵式飯盒や丸型飯盒を使った「飯盒炊爨」ですが、せ …